こんにちは。Jinnaiです。
今回はAzureCognitiveSearchのハイブリッド検索(キーワード検索+ベクトル検索)を試してみました。
今回は、[on your data]を使って比較的簡単にハイブリッド検索を試すことができたのでそちらの内容を記事にしたものです。
目次
Azure Cognitive Searchについて
Azure Cognitive Searchについては、すでに以下の記事でもご紹介をした通り、Microsoft Azureが提供する全文検索とAIを統合した検索サービスです。様々なデータ源から情報を抽出し、ユーザーが必要とする情報を迅速に提供することができます。

ハイブリッド検索とセマンティックランキングについて
新しい用語の解説
ここでAzure Cognitive Searchにおける、検索手法で本ブログで新しく登場する以下キーワードについて簡単に解説します。
ハイブリッド検索
キーワード検索とベクトル検索を組み合わせた検索方法です。キーワード検索は、ユーザーが入力した単語やフレーズと一致する文書を探します。ベクトル検索は、文書や単語を数値化したベクトルとして表現し、その類似度を計算して関連する文書を探します。ハイブリッド検索では、キーワード検索で絞り込んだ文書の中から、ベクトル検索で最も類似度の高い文書をランキングして表示します。
セマンティックランキング
セマンティックランキングはセマンティック検索機能の一つです。
ベクトル検索では文書やクエリを数学的なベクトルに変換し、その類似度に基づいて検索を行う方法でしたが、セマンティック検索では、自然言語処理や知識グラフなどの技術を用いて、ユーザーが入力した単語やフレーズの意味や関係性を分析します。単に単語やフレーズの一致だけでなく、同義語や類義語、上位語や下位語などの意味的なつながりも考慮して文書を探します。
このプロセスに続いて、セマンティックランキングは検索結果をユーザーのクエリに最も適合するように再ランク付けします。このランキングでは、文書の関連性だけでなく、その質や信頼性も考慮され、ユーザーにとって最も有用な情報が上位に表示されるように調整されるようです。
検索精度について
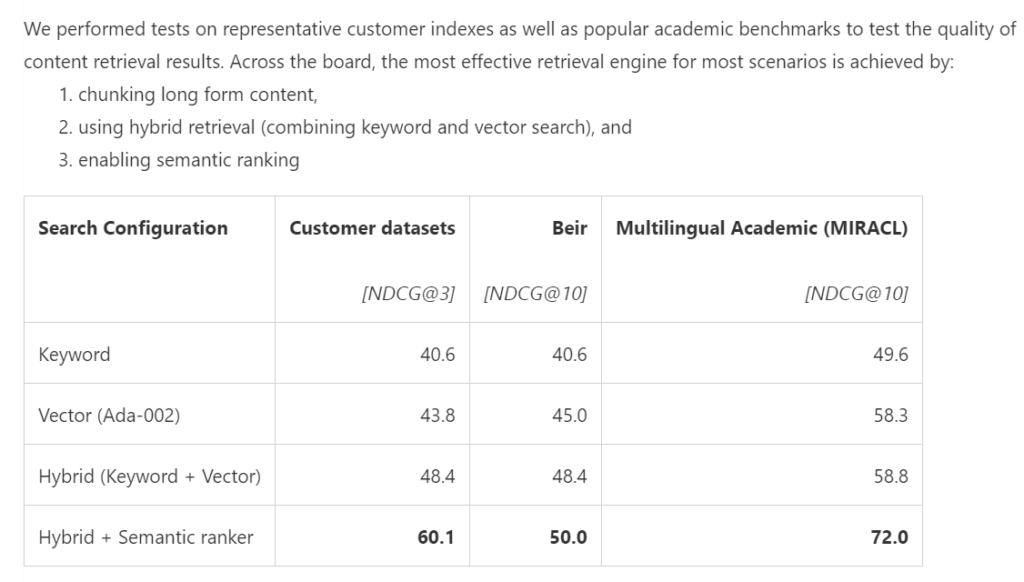
以下、Microsoftのドキュメントで公開されているのですが、以下サポートされている検索パターンにおいての検索精度を検証した結果が記載されています。
- キーワード検索
- ベクトル検索 (Ada-002)
- ハイブリッド検索 (キーワード + ベクトル)
- ハイブリッド検索 + セマンティックランキング

結論としては、以下の表に記載の通り、ハイブリッド検索とセマンティックランキングを組み合わせることで、検索結果の精度と関連性が最も高くなることがわかっています。
Azure Cognitive SearchとLlamaIndex
LlamaIndexは、高度な情報整理と検索機能を提供するツールで、ビジネスから教育まで、幅広い分野での活用が期待されています。 仕組みとしては、テキストデータをベクトル化する際、OpenAI社のEmbedding機能を利用しております。テキストを適切にチャンクし、埋め込みベクトル化することで、テキストと埋め込みベクトルを紐づけたノードを生成しており、これがインデックスの基盤となっています。
Azure Cognitive Searchでは、埋め込みベクトルを生成することはできませんので、Azure OpenAI またはその他のモデルを使ってベクトル変換する必要があります。
ですので、テキストデータをベクトル化して検索機能を提供する点では、LlamaindexとAzure Cognitive Searchのベクトル検索は似たような仕組みを利用していることがわかります。
ハイブリッド検索を試してみる
それでは、実際に試していきたいと思います。
今回は[on your Data]を使ってBlob Storage上にあるドキュメントを検索したいと思います。
モデルのデプロイ
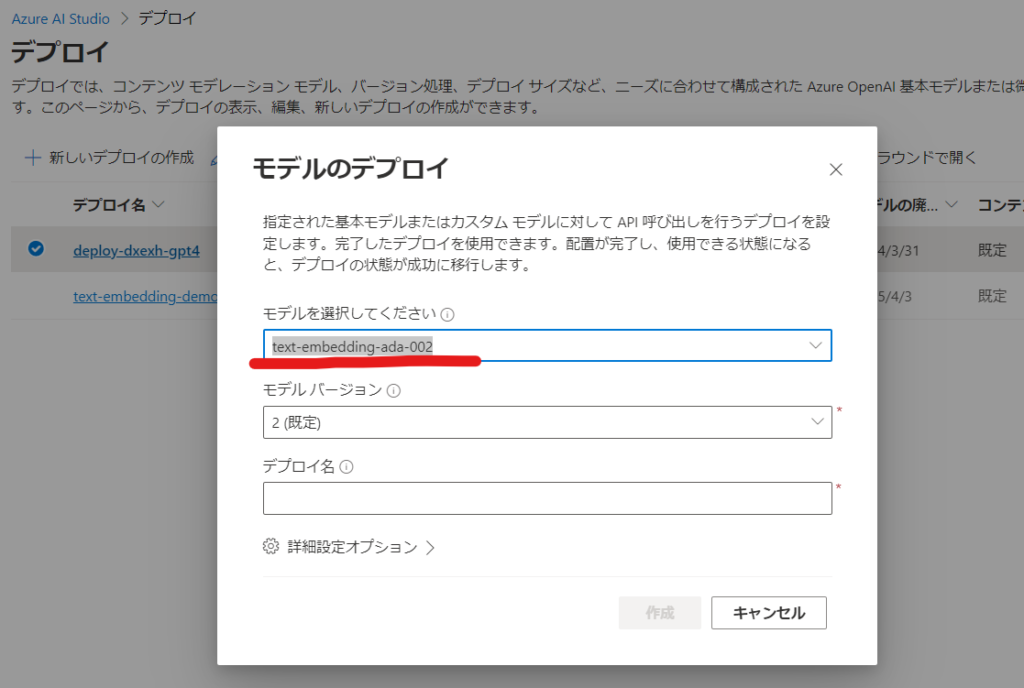
Azure AI Studioで新しいデプロイを作成します。
ハイブリッド検索を実現するためには、モデルは[text-embedding-ada-002]を選択する必要があります。
これは、Llamaindexでも同様の話になりますがベクトル検索を実現するためには、Embeddingを行う必要があるためです。
on your data(データの追加)
Azure AI Studioのプライグラウンドメニューにて、[チャット]を選択し、[on your data](日本語だとデータの追加)を選択します。
ドキュメントを格納したAzure Blob Storageを選択し、赤線の[ベクトル検索をこの検索リソースに追加します]にチェックを入れます。
すると、埋め込みモデルの選択メニューが出てくるので先ほど作成した[text-embedding-ada-002]モデルのデプロイしたリソース名を選択します。
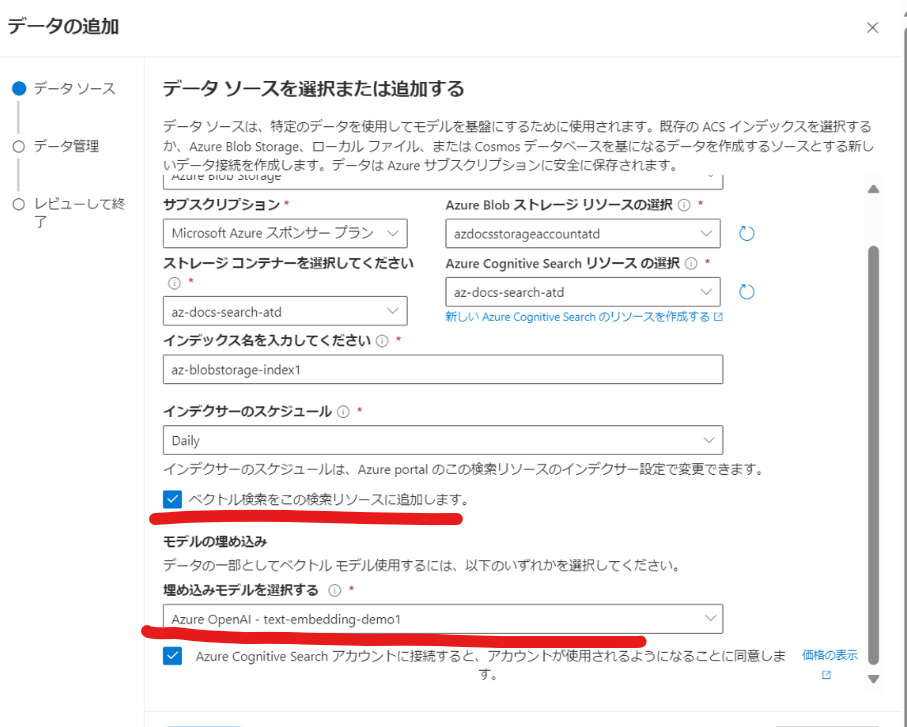
次に進むと[検索の種類]を選択できるため、[ハイブリッド(ベクトル+キーワード)]を選びます。
自動作成されたインデックスの確認
データの追加が完了するとインデックスとインデクサーが自動生成されます。
ここで注目していただきたいのは、インデックスとインデクサーが2つ作成されることです。以下は実際のインデックスになります。
赤線はキーワード検索、青線がベクトル検索のためのインデックスと思われます。

今回、AzureBlobStorageに格納したドキュメントは2つです。
単純にドキュメントに対してキーワード検索を行うのであれば、インデックスのドキュメント数は2つになるはずなので、赤線のインデックスがキーワード検索に該当するインデックスです。
一方で青線のインデックスですがドキュメント数が20になっています。実はEmbeddingによってテキストと埋め込みベクトルを紐づけたデータがドキュメントを格納した場所と同じAzure Blob Storageのコンテナー上に作成されます。(黄線)
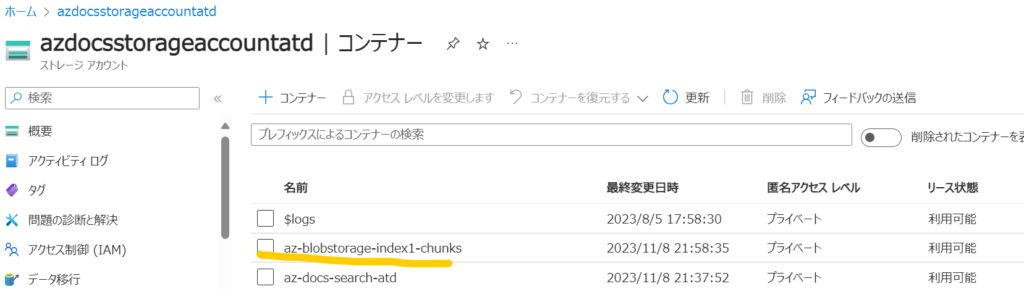
実際に中身を見てみると、20個のデータが格納されていることがわかります。
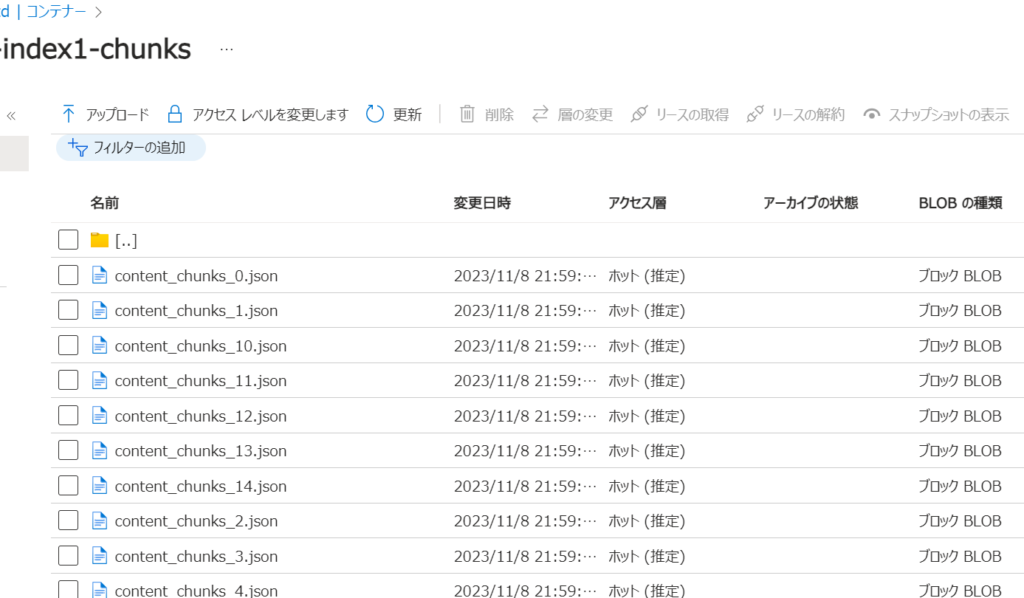
さらにjsonファイルのデータを確認してみると、キーワードとそれに対応する埋め込みベクトルが記載されていることがわかります。
[[0.010022971779108047, -0.00974704697728157,]などのように表現されている数列はテキストの意味を数学的に表現しているものです。この埋め込みベクトルによってテキストデータをより、洗練された検索や分析が可能になります。
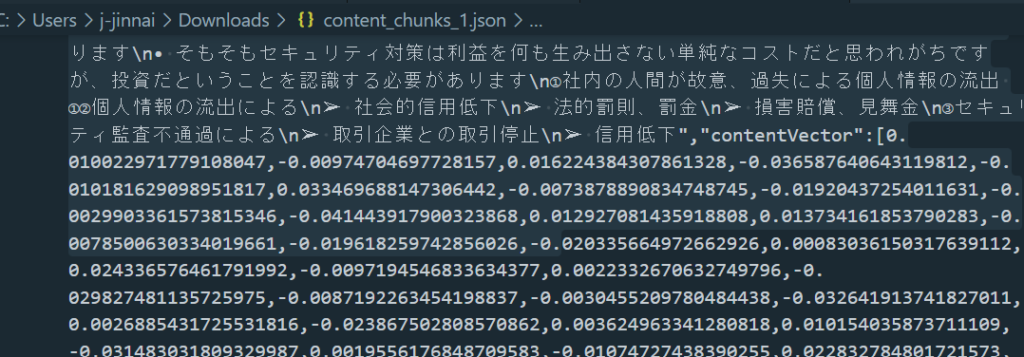
実際の検索結果
キーワード検索では、あいまいな質問をしても回答すらしてくれなかったのですが、このハイブリッド検索では、かなり、資料に記載している内容を正確に読み取って回答しています。
終わりに
いかがでしたでしょうか?
当社、ATD InnoSolutionsではAzure Cognitive Searchのほか、LlamaIndexなども活用して生成AI活用の支援も行っています。
開発相談、協業に関しては是非お気軽にHPへお問合せください。